첫 번째 예제에서는 하나의 페이지 안에서 크롤링을 해보았다.
[크롤링, 예제 1] 문제풀이 사이트 정답율 추출하기
아래 포스팅을 읽지 않았다면 무조건 읽고 올 것을 권장한다. 설치법과 robots.txt같이 필수적으로 알아둬야 하는 개념이 필요하다. kimcoder.tistory.com/164 크롤링을 위한 준비과정 (Python, selenium, beautif
kimcoder.tistory.com
이제 두 번째 예제에서는, 여러 페이지(링크)들을 넘나들며 데이터들을 긁어올 것이다.
또, Selenium을 이용할 것이고 크롤링 도중 새 창이 뜨게 하지 않을 것이다. 이를 위해서 예제 1-3 포스팅도 읽고 오는 것을 권장한다.
[크롤링, 예제 1-3] Selenium - 새 창 안띄우고 크롤링 하기
저번 포스팅에서의 Selenium 예제에서는 get함수에 의해 새 창이 실행되고, 크롤링 도중에 그 창을 지우면 크롤링이 진행되지 않는다. <저번 포스팅> kimcoder.tistory.com/166 [크롤링, 예제 1-2] 예제 1 - 셀
kimcoder.tistory.com
예제 1에서 했던 것 처럼 차근차근 절차를 밟아가보며 크롤링해보자.
0. 크롤링 계획 세우기
Programmers에서 코딩 테스트 고득점 Kit는 10개의 카테고리 안에 총 36문제로 구성되어 있고,
SQL 고득점 Kit는 6개의 카테고리 안에 총 27문제로 구성되어 있으며, 각 문제들은 Level1~Level5로 나뉜다.
Programmers에 있는 코딩 테스트 고득점 Kit와 SQL 고득점 Kit의 모든 문제의 레벨(난이도) 분포를 구한다.
1. 크롤링할 페이지 접속
/learn/challenges 로 접속했다. (programmers.co.kr/learn/challenges)

programmers.co.kr/learn/challenges
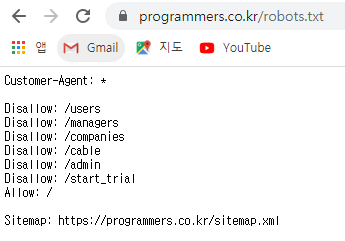
2. 크롤링 가능 여부 확인(필수)
Disallow에 /learn이 없으므로 불법x
게다가 Disallow 이외의 것들은 Allow라고 표기되어있다.
3. 크롤링할 대상 결정
메인 화면에서는 문제 난이도를 확인할 수 없고, 카테고리마다 직접 들어가줘야 한다.
본인이 빨간 상자로 표시해둔 카테고리로 들어가보자.

대표로 '해시' 카테고리로 들어가보았다.
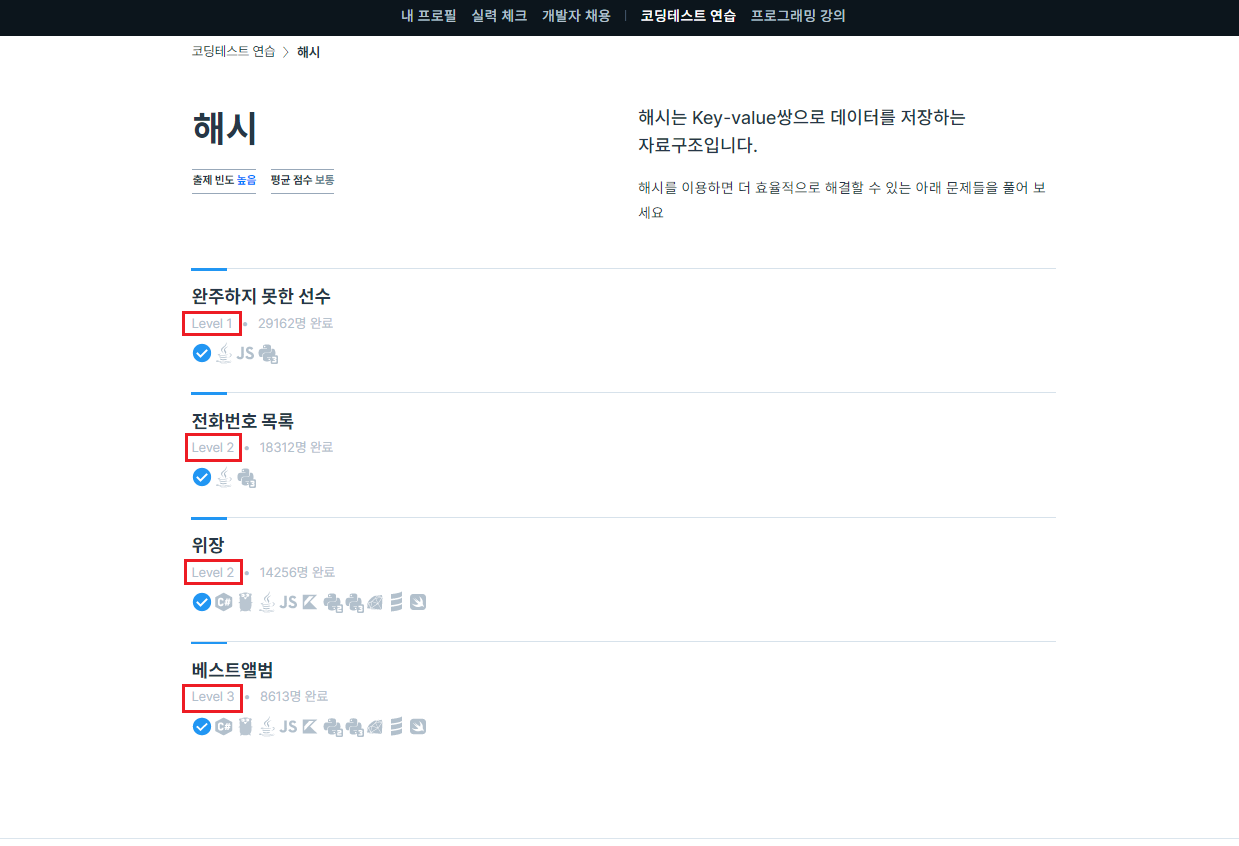
'해시' 카테고리에 있는 4문제의 난이도는 각각 1,2,2,3 인 것을 알 수 있다. 이렇게 모든 카테고리 페이지에 들어가서 모든 문제들의 난이도를 확인할 수 있다.
4. 크롤링할 데이터가 있는 태그 파악
코딩 테스트, SQL의 고득점 Kit들의 카테고리에 접속하는 것도 자동화가 필요하다.
먼저 카테고리의 링크들을 모아둔 후 한꺼번에 여러 페이지의 레벨 데이터들을 추출하는 방법이 좋을 것 같았다.
웹 코드, 웹 요소 태그 위치 확인법은 이전 포스팅에서 설명했으니 생략하도록 한다.
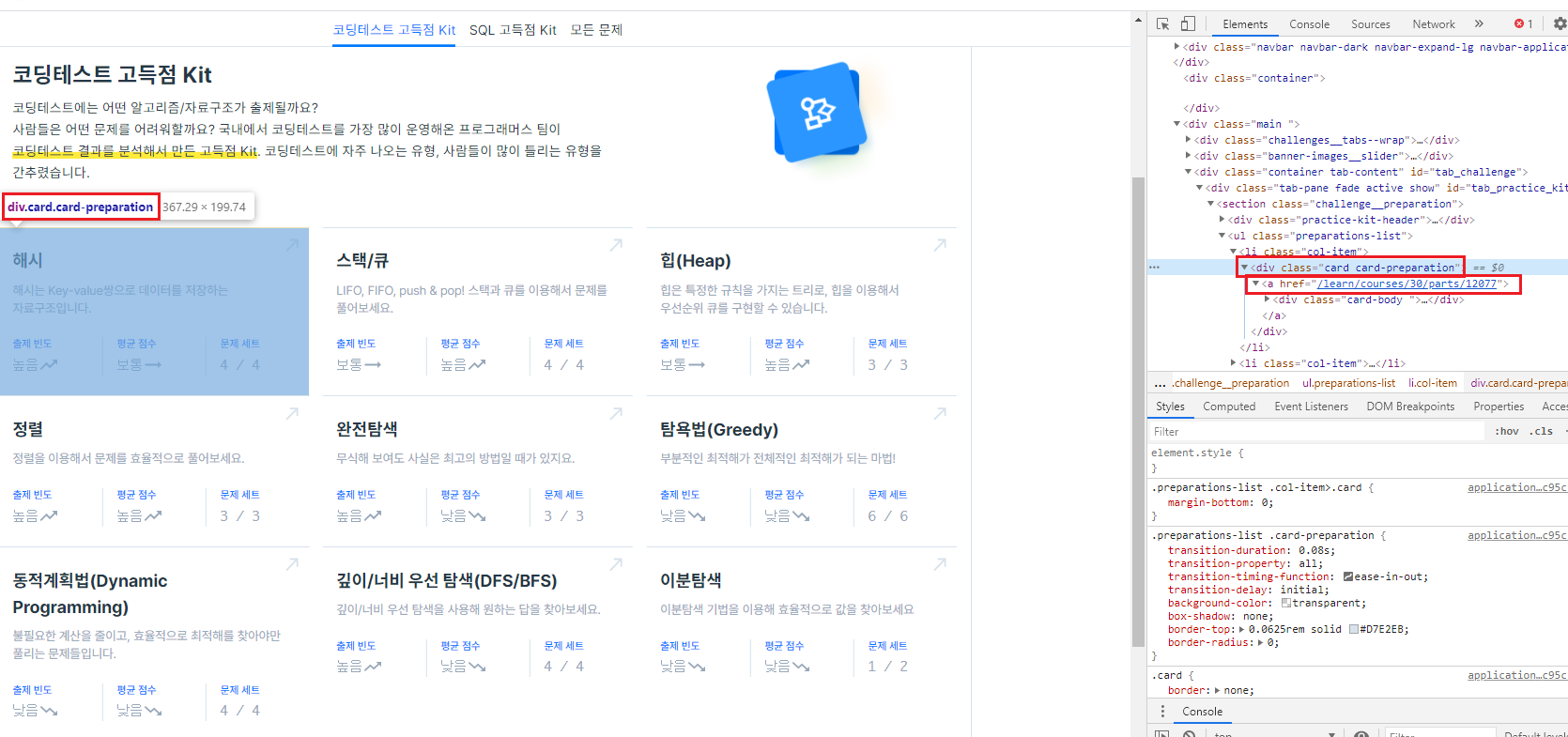
<카테고리 링크 확인>
아래 사진을 보면 class가 "card card-preparation"인 <div>태그의 안에 있는 <a> 태그의 href 속성에 카테고리의 링크가 있는 것을 확인할 수 있다.
class도 띄어쓰기를 경계로 여러 class로 표기할 수 있는데, 이 때는 inspect 상태에서 웹 요소를 직접 클릭해봐서 정확한 코딩용 표기법을 확인하는 것이 좋다. ('card.card-preparation')
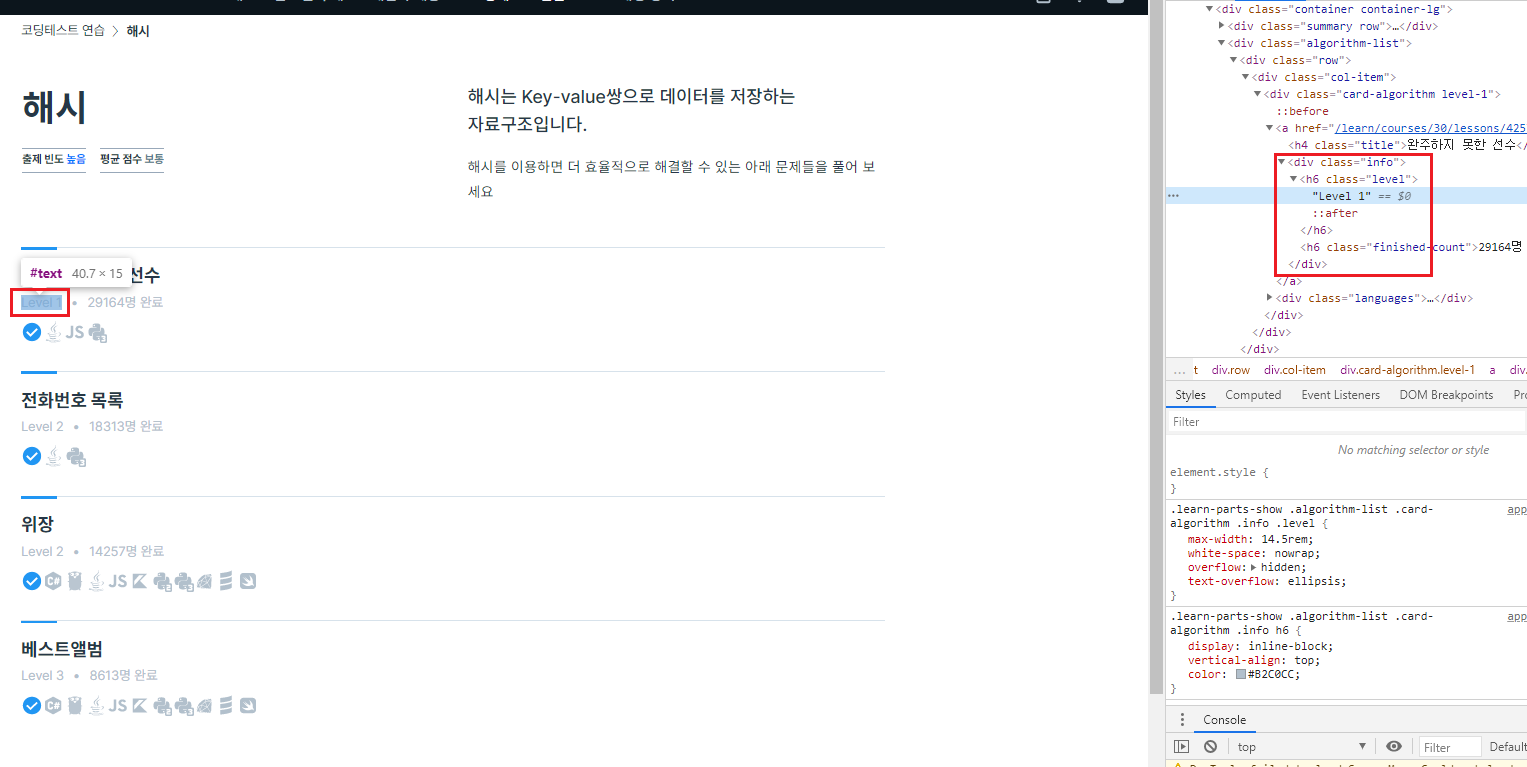
<카테고리 내에서 원하는 데이터가 있는 태그 확인>
5. 태그 규칙 파악
원하는 데이터는 <h6> 태그 안에 "Level x" 라는 형식으로 존재한다.
그리고 <h6> 태그는 class가 "info"인 <div> 태그로 감싸져 있다.
class가 "info"인 <div> 태그는 카테고리 페이지 내에 하나 뿐이므로 그 이상의 상위 태그는 고려하지 않아도 된다.
규칙 : 원하는 데이터는 class가 "info"인 <div> 태그 내에서, class가 "level"인 <a> 태그의 text로 존재한다.
6. 코딩
challengelinks 배열을 생성하여 코딩 테스트 고득점 Kit, SQL 고득점 Kit의 url을 넣어주고 이들 각각의 모든 카테고리 링크들을 크롤링으로 찾아서 links 배열에 따로 모아두었다.
그리고 그 링크들의 각 페이지에 있는 모든 문제 레벨들을 크롤링으로 찾아서 challengelevels 배열에서 카운트하며 분포를 구한다.
모든 과정은 주석으로 설명해두었다.
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('lang=ko_KR')
driver = webdriver.Chrome('C:\chromedriver\chromedriver.exe',chrome_options=chrome_options)
#챌린지 제목
titles=[]
titles.append("Coding Test High Score Kit")
titles.append("SQL High Score Kit")
#챌린지 별 카테고리 링크
links=[[],[]]
#레벨 별 문제 분포 카운트
challengelevels = [[0,0,0,0,0],[0,0,0,0,0]]
#챌린지 링크
challengelinks = []
challengelinks.append('https://programmers.co.kr/learn/challenges?tab=algorithm_practice_kit')
challengelinks.append('https://programmers.co.kr/learn/challenges?tab=sql_practice_kit')
#(인덱스, 챌린지 링크) 쌍
for i,challengelink in enumerate(challengelinks):
#카테고리 링크 추출 작업
driver.get(challengelink)
html = driver.page_source
soup = BeautifulSoup(html,'html.parser')
selected_links = soup.select('div.card.card-preparation a')
for link in selected_links:
links[i].append('https://programmers.co.kr'+link.get("href"))
#카테고리 내 문제들의 레벨 데이터 추출
for link in links[i]:
driver.get(link)
html = driver.page_source
soup = BeautifulSoup(html,'html.parser')
levels = soup.select('div.info h6.level')
for level in levels:
# "Level x" 에서 x를 추출하여 레벨 별 문제 수 1카운트
challengelevels[i][int(level.text[6])-1]+=1
#결과 출력
for c in range(0,len(challengelevels)):
print('\n'+'<'+titles[c]+'>')
for l in range(0,5):
print('Level'+str(l+1)+' has '+str(challengelevels[c][l])+' Questions')
7. 실행
드디어 즐거운 결과 확인 시간이 돌아왔다.

코딩 테스트 고득점 Kit 총 36문제와 SQL 고득점 Kit 총 27문제의 레벨 분포가 정확히 계산되었다.
코딩 테스트 고득점 Kit 문제들은 주로 2~3레벨에 분포되어 있고,
SQL 고득점 Kit 문제들은 주로 1~2레벨에 분포되어 있으며,
평균 문제 레벨은 각각 2.47, 1.93임을 계산하여 확인할 수 있었다.
'Crawling' 카테고리의 다른 글
| [크롤링, 예제 4] Youtube - 필터를 적용하여 영상 목록 보기 (0) | 2020.11.02 |
|---|---|
| [크롤링, 예제 3] 게임 포럼 사이트에서 정보 긁어오기 (+그래프) (0) | 2020.10.31 |
| [크롤링, 예제 1-3] Selenium - 새 창 안띄우고 크롤링 하기 (0) | 2020.10.23 |
| [크롤링, 예제 1-2] 예제 1 - 셀레니움(Selenium) 이용 (0) | 2020.10.23 |
| [크롤링, 예제 1] BOJ 정답율 추출하기 (11) | 2020.10.23 |




댓글