이번 포스팅에서는 Node.js에서 request, cheerio 모듈을 이용하여, 백준 온라인 저지 사이트에 있는 특정 문제들의 정답률 데이터를 모두 긁어와서 평균까지 계산해주는 크롤링 봇 구현에 대해 다룰 것이다.
지나친 크롤링은 웹사이트에 트래픽을 줄 수 있으므로 가볍게 모든문제 1페이지에 있는 문제번호 1000~1099까지 총 100문제의 정답률 데이터들만 추출해보자.
프로젝트 폴더 내에 request, cheerio 모듈을 설치해줘야 한다.
npm install request --save
npm install cheerio --save
html코드를 가져오고 싶은 사이트의 url을 request의 매개변수에 넣고,
let $ = cheerio.load(body) 로 html코드를 최종적으로 세팅하면 준비는 끝이다.
크롤링에 있어서 핵심은 html코드 안에서 원하는 데이터를 감싸는 태그들의 규칙을 찾는 것이다.
크롬 브라우저에서 우클릭 - 검사로 웹 코드를 볼 수 있다.
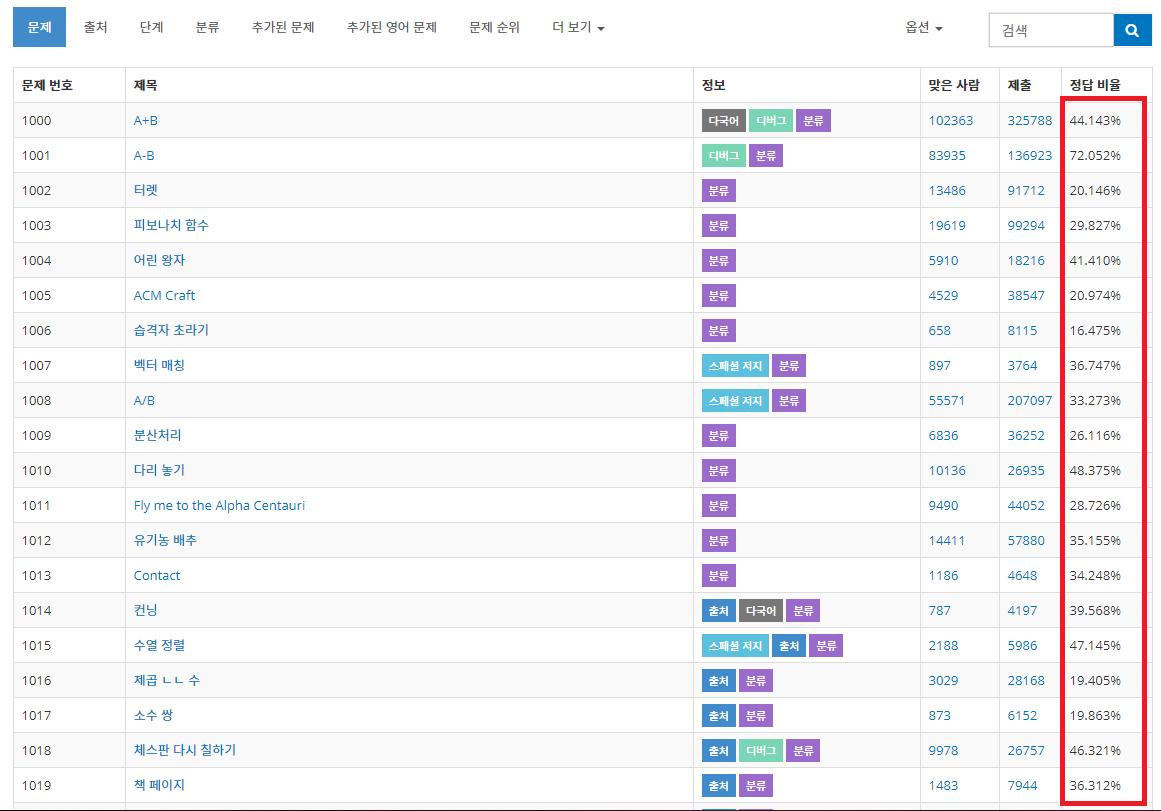
웹 코드를 보면 원하는 데이터인 "44.143%"가 여러 태그들에 의해 감싸져 있는 것을 볼 수 있다.
웹 코드에서 tbody -> tr -> 6번째 td 에 정답률 데이터가 있다는 사실을 알 수 있다.
웹 코드에서 tbody 태그는 하나 뿐이므로, 안심하고 다른 조건 지정없이 tbody를 사용했다.
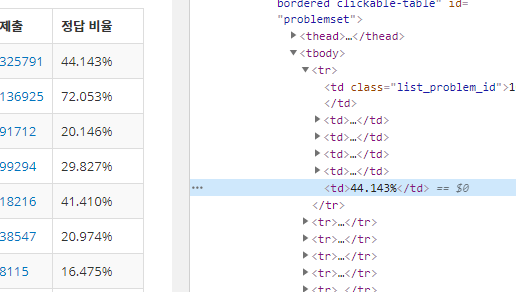
이를 소스코드로 나타내면 이렇다.
html, css, javascript에 어느정도 지식이 있다면 쉽게 이해할 수 있을 것이다.
핵심은 12번 째 줄에 있는 선택자 'tbody tr td:nth-child(6)' 이다. (tbody -> tr -> 6번째 td)
const request = require('request');
const cheerio = require('cheerio');
const { doesNotThrow } = require('assert');
const url = "https://www.acmicpc.net/problemset/1";
request(url, (error, response, body) => {
if (error) throw error;
let $ = cheerio.load(body);
try{
var sum=0;
var size=0;
$('tbody tr td:nth-child(6)').each(function(index,elem){
var rate_text = $(this).text(); //해당 태그의 text부분만 잘라오기
var filtered_rate_text = rate_text.substring(0,rate_text.length-1); //'%'자르기
var rate = parseFloat(filtered_rate_text); //문자열 형태의 정답률을 float형으로 변환
console.log(rate);
sum+=rate;
size += $(this).length;
});
console.log('Size=' +size);
console.log('Average Correct Percentage=' +(sum/size).toFixed(3)+'%');
}
catch(error){
console.error(error);
}
});

1000~1099번 문제의 정답률 평균은 약 32.536% 이라는 것을 알 수 있다.
정답률 양식과 같이 소수 3번 째 자리 까지 표시했다.
'Node.js > Node.js Basic' 카테고리의 다른 글
| [Node.js] 객체를 파일 단위로 관리하기 (0) | 2020.10.19 |
|---|---|
| [Node.js] 파일 삭제 (0) | 2020.10.15 |
| [Node.js] 파일생성/파일명변경, redirection (0) | 2020.10.14 |
| [Node.js] URL의 query string 추출 (POST방식) (0) | 2020.10.13 |
| [Node.js] 파일 조회/읽기/parse (File path 간단 설명) (0) | 2020.10.06 |




댓글